标题:可解释的视频异常定位
文章链接:https://arxiv.org/abs/2212.07900
这是一篇关于静态视频异常检测的论文,在CVPR上翻到的,和研究方向有关系,就拿过来读了。
首先看一下文章摘要:
Abstract: We develop a novel framework for single-scene video anomaly localization that allows for human-understandable reasons for the decisions the system makes. We first learn general representations of objects and their motions (using deep networks) and then use these representations to build a high-level, location-dependent model of any particular scene. This model can be used to detect anomalies in new videos of the same scene. Importantly, our approach is explainable – our high-level appearance and motion features can provide human-understandable reasons for why any part of a video is classified as normal or anomalous. We conduct experiments on standard video anomaly detection datasets (Street Scene, CUHK Avenue, ShanghaiTech and UCSD Ped1, Ped2) and show significant improvements over the previous state-of-the-art. All of our code and extra datasets will be made publicly available.
作者的目的就是为实现单一场景视频下的异常定位,以及提供一个可信的理由告诉人们为什么这里有异常。
研究背景
与通过视频帧重构的方法不同,作者的方法直接从视频帧中提取特征信息,然后将这些信息直接用于异常检测。这也是本文最大的贡献。
作者提到了人类观看监控视频时是如何判断出画面里出现了异常的:人会注意到某个物体或其运动状态和之前看到的不一样了,并且他还能向人解释为什么这个是异常的。
作者在 1. Introduction 里为视频中的异常下了一个定义(为数不多有定义的论文):
Definition: An anomaly is any spatio-temporal region of test video that is significantly different from all of the nominal video in the same spatial region.
(异常是任何与同一空间区域中所有标称视频存在显著差异的时空区域。)
方法论
如何通过模型算法量化出这些显著差异呢?
在 3. Our Approach 一节中,作者将这个工作分成了三个部分:
- 高级属性学习(high-levelattribute learning)即特征提取步骤
- 模型搭建(model building)
- 异常定位(anomaly localization)
先来看模型搭建部分,在这一部分作者又提出“模型构建流程”和“异常定位流程”:
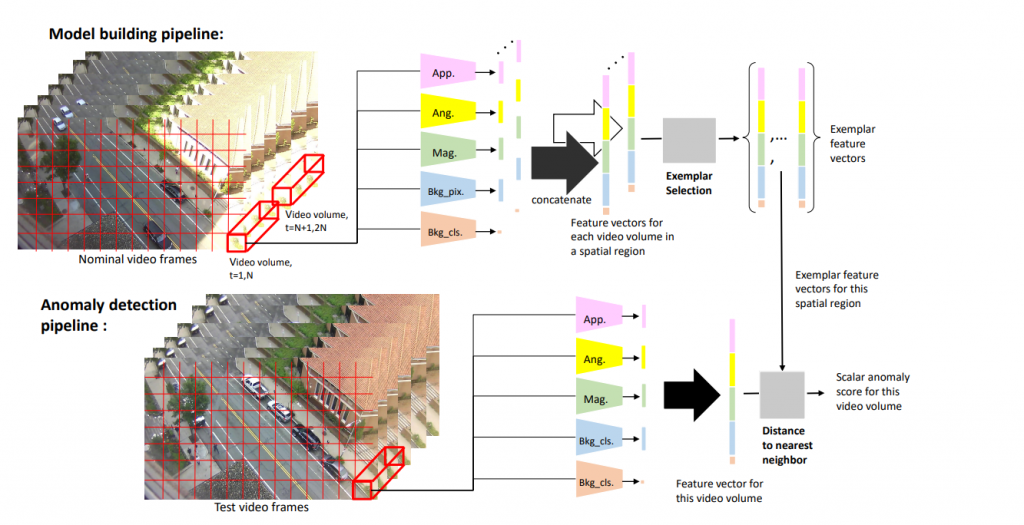
模型构建流程
作者将视频划分为若干个小区域,每个小区域的长宽分别为 h 和 w ,然后每个小区域又同时选中视频的 t 帧,这样一个 [h × w × t] 的视频块(Video Volume,我也不知道怎么翻译好)。作者取 h=w,以及 h 大致为特定场景下人物的像素高度。
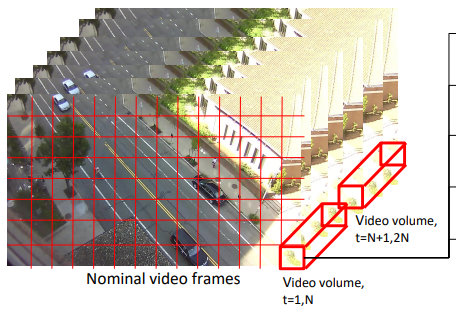
每次滑动这个窗口,步长为 (h/2, w/2),时间步长为 t/2,每次处理视频块内的像素,通过特征提取步骤提取出五个特征向量,分别是 App, Ang, Mag, Bkg_pix. 和 Bkg_cls.
这个”特征提取步骤”是什么呢?
在3.1节高级属性学习中提到,一共分为两个小模型,分别是外观模型(Appearance model)和运动模型(Motion model)。
外观模型(Appearance model)
外观模型就负责为该视频块内的像素进行一个多分类任务的归类,旨在说明这个物体大概是什么。
作者定义了一个初始对象类别集——[人、汽车、骑行者、狗、树、房子、摩天楼和桥],一共为8种物体,老实说这个分类其实是比较粗糙的。
作者使用的网络架构是以ResNeXt-50为主干网络,然后在其基础上进行一定的修改。
作者在ResNeXt-50的最后一层添加了一个额外的全连接层,将平均池化层之后的2048维特征向量映射到一个128维的层(输出高级特征),然后,这个128维的层通过最后一个全连接层映射到一个8维的输出层(输出高级属性)。
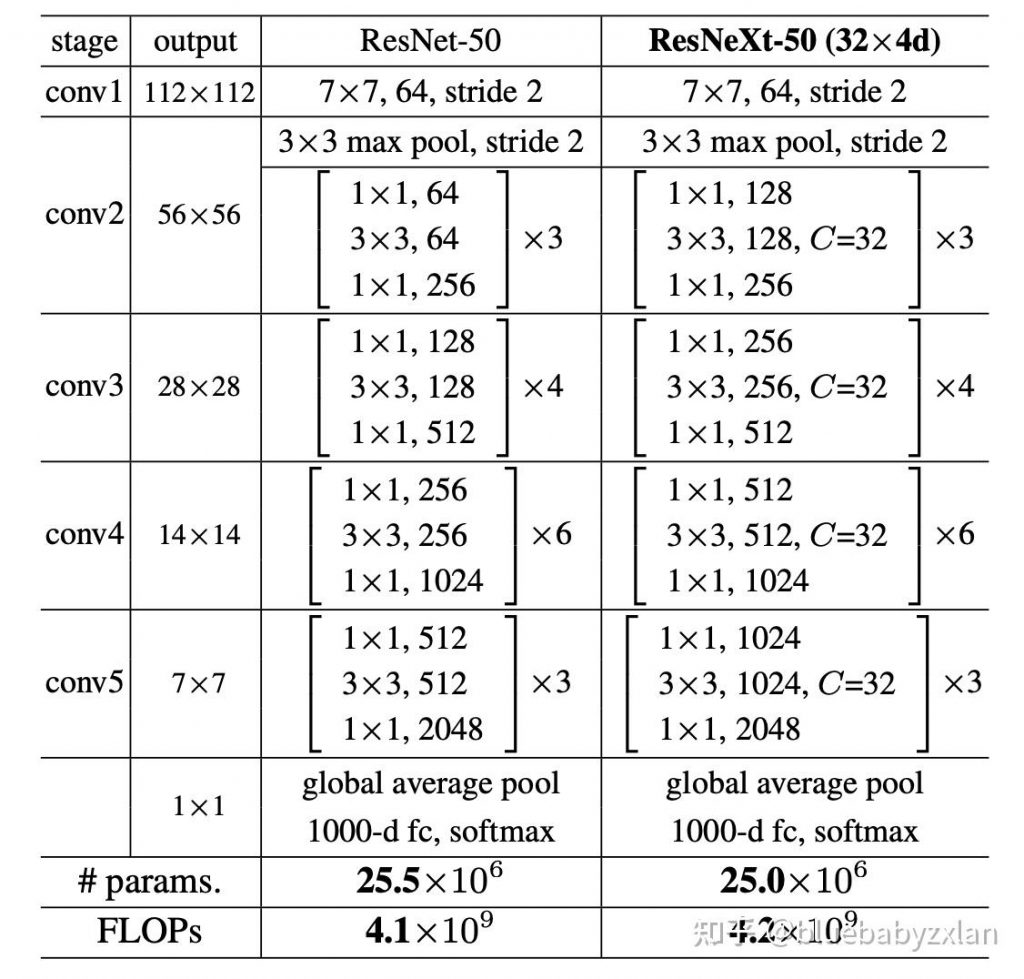
平均池化层后将输出维度1000-d改为了128-d
并加了全连接层,最后是8-d输出
模型使用的激活函数为Sigmoid函数,loss为二元交叉熵。
运动模型(Motion model)
一句话概括,运动模型负责描述视频中目标的运动状态。
运动模型会输出4个属性,分别是 Y_ang、Y_bkg、Y_mag 和 Y_bkg.cls。
首先是使用TV-L1(查了一下是用于图像降噪的)方法并计算每个像素点的光流场(pixelwise optical flow fields)。
在这里用到了光流(optical flow)。光流是图像亮度的运动信息描述,描述一个场景中的物体,由于运动(物体本身运动,相机运动)而在连续两帧间动态变化的方法。其本质是一个二维向量场,每个向量表示了场景中该点从前一帧到后一帧的位移。那对于光流的求解,即输入两张连续图象(图象像素),输出二维向量场的过程。<来自啥是TV-L1 OpticalFlow – 知乎 (zhihu.com)>

光流场有12个bins,计算光流向量与横轴的夹角,并把计算的夹角结果分配到各自的bin(这里面每30度定义一个bin),可以得到长度为12的一维向量。
如果一个视频块里的像素几乎没有“运动”,那么这个视频块的 Y_bkg.cls 就是 1,表示这块区域是背景。
接着作者计算了13个bin的归一化直方图(13-bin normalized histogram)
- Y_ang 为前12个bins值组成的向量,为流方向(flow orientation)在每30度里的像素数量(文中式子 [i × π/6, (i+1) × π/6), i ∈ [0, 11])
- Y_bkg 为最后一个bin的值,为流强度(flow magnitude)低于阈值的像素数量
- Y_mag 为在12个流方向上每个方向内像素的平均流强度
之后对Y_ang、Y_bkg、Y_mag这3个属性分别进行训练,训练用的网络是一样的,但是目标函数(在这里即损失函数)不相同。作者将其作为回归任务来训练,Y_ang 用的 KL散度损失函数,Y_bkg 和 Y_mag 用的 均方误差损失函数。
网络的结构为 3D卷积(3DConv)- 批量归一化(BN)- ReLU激活函数 [3Dconv-BN-ReLU],最后用全连接层映射到128维的向量上。
特征提取步骤就差不多到头了,但是我们看图里提取出来的特征有5个诶,分别是 App、Ang、Mag、Bkg_pix和Bkg_cls。Bkg_pix和App是怎么来的呢?
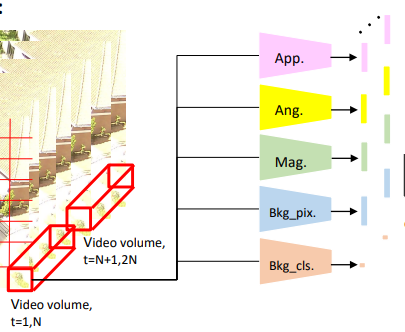
App其实就是外观模型倒数第二层的输出,为128维的特征向量。
Bkg_pix其实就是Y_Bkg经过网络训练后的特征输出,流强度低于阈值的像素数量也是一种侧面反映其是否为背景的依据。
各空间区域特征集的构建
在3.2节,作者揭示其中App、Ang、Mag、Bkg_pix的尺寸均为1×128,再和二元量Bkg_cls统合在一起,得到一个 1×513 的总的特征向量,如下图所示。
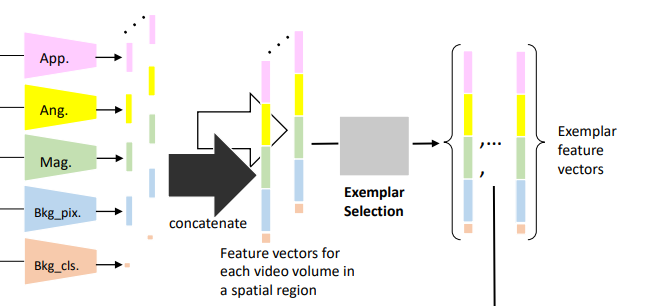
一个视频块里是包含了很多帧的,为了使一个视频块获得单一特征向量,作者这里把这 t 帧的特征向量取了平均。
但是这个空间区域仍然会得到很多特征向量,于是对每个区域作者做了一个贪婪样本选择算法:
- 将第一个特征向量添加到样本集中
- 对于每个后续的特征向量,计算它与样本集中每个特征向量的距离,并且仅当所有距离都高于阈值th时,才将其添加到样本集中
这样能使特征向量更具代表性,使特征集更加紧凑以及丰富。
于是对视频上的每个区域,都有一组特征集。
特征向量之间的距离又怎么算呢?
对于该距离的计算,设两个特征向量F1和F2:
F1 = [app1; ang1; mag1; bkg1; cls1]
F2 = [app2; ang2; mag2; bkg2; cls2]
特征向量前四个部分两两之间计算L2距离(欧式距离),并归一化使每个距离最大值大约为1。假如该视频块里不包含运动,距离就是0。作者给出的距离公式如下:
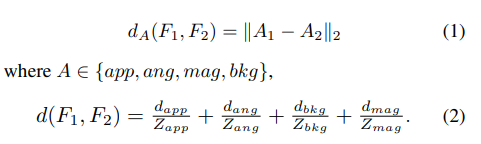
d_xxx 为各部分的距离,Z_xxx是该部分最大的距离,从验证集中算出,仅计算一次。
这种方法可以流式更新样本集(updating the exemplar set in a streaming fashion),随着新数据的到来逐步增加或替换样本集中的元素,而不需要重新处理整个数据集,并随着时间的推移适应环境的变化。
至此,一个能进行异常检测和定位的模型就构建完毕。
异常检测流程
把异常检测流程图再贴过来:
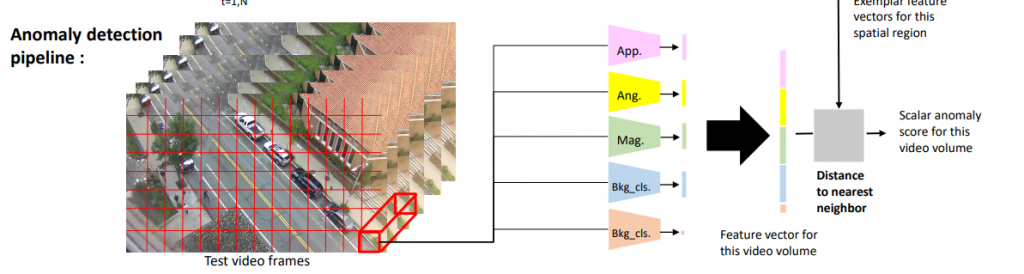
处理测试视频提取特征向量时,和训练模型时是同样的视频块尺寸 [h×w×t],同样的步长 (h/2, w/2), 同样的时间步长 t。
同样的特征提取方法得到每个视频块的特征向量,与该视频块同样区域的样本集内特征向量计算最小距离(Distance to nearest neighbor)(使用公式2)。
这样会得到一个标量异常分数(Scalar anomaly score),分配给该区域所有像素。
由于步长只有每个区域尺寸的一半,所以必然会产生重叠。
如果发现某个像素已经被分配了一个异常分数,则和新计算出来的异常分数做比较,然后取最大值。
该方法对于异常的判断也很简单,如果一帧中某个部分的异常分数大于阈值,则该部分就出现了异常。
作者在第4节给出了实际操作时的各变量的图,如下图所示。
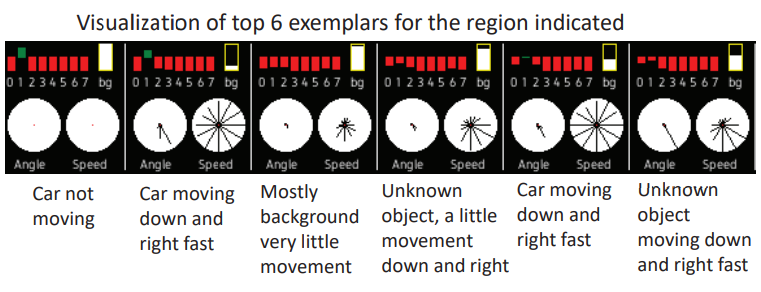
左上角 0-7 就是 App,表示物体是什么,如果大于0.5(绿)表示很可能是这类的物体。
右上角 bg 就是 Bkg_pix,这个地方”没有运动”的像素量。越白说明越”静止”,越黑则越”运动”。
左下角 Angle 就是 Ang,视频块内像素”运动”的方向。12个方向上的射线长度与估计在该方向上移动的像素数量成正比。
右下角 Speed 就是 Mag,通过定向速度网络(directional speed network)计算得出的每个方向上”运动”的强度。
综上,就能以此描述一个物体以及其运动的状态。
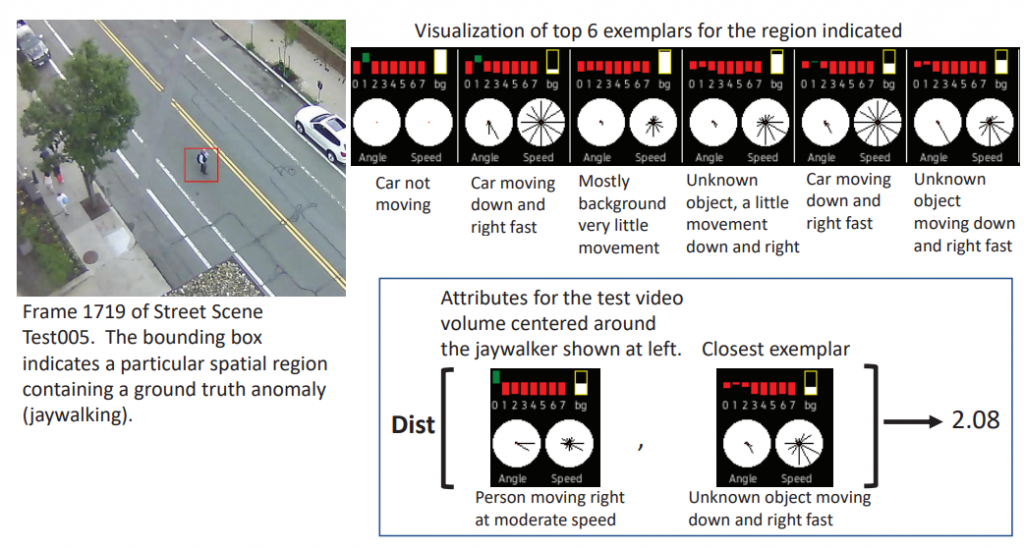
如上图所示,正常的样本集内的exemplar大多是“未知物体快速向右下方移动(Unknown object moving down and right fast)”,但是此时出现了”人以正常速度往右移动(Person moving right at moderate speed)”,和最接近的正常样本比较,得到的距离为2.08。然后设定阈值来判断是否属于异常即可。