标题:利用伪标签的完整性和不确定性进行弱监督视频异常检测
论文来源:CVPR 2023 Open Access Repository (thecvf.com)
这篇论文也是关于视频异常检测的,在传统基于多实例学习(MIL)的two-stage检测算法的基础上进行了一定的创新。
目前公开的很多异常视频数据集的标签都是视频级的。换句话说,一个含有异常事件的视频,它就只有一个标签:是否含有异常事件。
但是对于视频异常检测往往都需要进一步定位视频里异常出现的时间和位置,这个标签往往都需要人自己去做。如果手动去一帧一帧看,一帧一帧打标签,去生成“帧级别”的标签,成本巨大,不现实。所以通过训练模型,让模型对视频生成更细的片段级“伪标签”的方法,然后用这些伪标签进行异常检测模型的训练方法被提了出来。
这里提到的基础异常检测算法是先对视频提取特征,然后根据特征生成片段级伪标签,从而利用视频和伪标签进行模型的训练
但是很多时候让模型生成伪标签会出现一些问题。文中提到两个点,分别是伪标签的不完整性和不确定性。
何为伪标签的不完整性?多实例学习由于缺乏帧级别的标签,这个“硬伤”会导致结果的必然不准确,在生成伪标签的时候,往往只去注意视频里最有可能是异常的一小段,标出来的异常可能就不完整,标签也是不完整的,如下图所示。
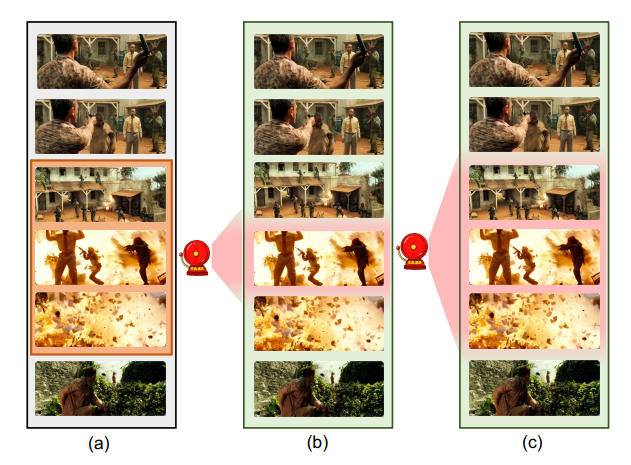
何为伪标签的不确定性?模型自己去给异常视频打标签,往往会不准确,有些不是异常的被标为异常,某些是异常的又没标上,简而言之得到的标签集是“有噪声的”,直接用来训练会影响分类器性能。
对于这两个不足之处,作者提出两个改进策略,第一个是多头分类器模型(multi-head classification module),第二个是不确定性伪标签迭代提炼策略(iterative uncertainty pseudo label refinement strategy,英语不好不会翻译)。
关于多头分类器,就是将视频切片后提取出来的片段特征集传给多个头,每个头分别去注意视频中不同的异常片段,通过不同的损失函数使多个头的结果合并成一份理想的异常片段伪标签集,使异常标签覆盖到尽可能多的异常片段上,也即尽可能多地检测出有异常事件的片段。
关于不确定性伪标签迭代提炼,也即经过多次迭代,从而提炼出低不确定性的伪标签,这些伪标签对于描述该片段是否含有异常事件会更加准确。迭代挖掘低不确定性伪标签的同时也在通过MC-dropout每次都训练模型中一部分神经元,输入即为这些不确定性更低的伪标签,通过不断迭代训练,最终得到能有效检测出异常的模型。
整个训练过程如下图所示。
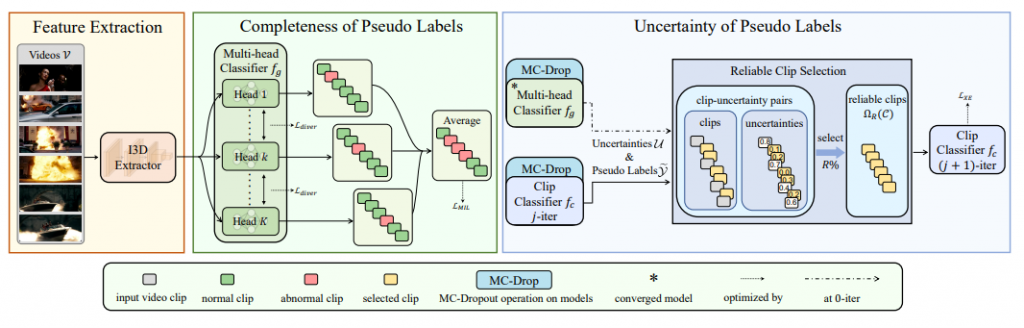
作者随即分别详细解释了图上三个部分的工作是如何完成的。
1. 左边黄色部分 (Feature Extraction)
这部分说明在文章的3.1节。
首先给定有视频级异常标签的视频集,以其中一个视频为例,将其每 16 帧切一次片,假设这个视频被切成了 T 份。现在我们得到了一份切碎了的视频片段组成的集合。
将这个集合里面的每一份切片,都过一遍 3D CNN ,提取出其中的特征。这样我们就得到了一份由 T 个特征组成的特征集。每个特征(向量)的维度都是一样的。
由于不同视频长短不一,切出来的片段数量通常不一致,提取特征得到的特征向量数量也不一样,不方便训练,因此把这些特征都拼在一起,重新切成 S 个特征(就像把 T 根水管重新接在一起,然后再重新切成 S 根)。
每个视频都这样做一遍,每个视频都能得到一个含有 S 个特征向量的集合。至此特征提取部分就结束了。
作者在这里将异常视频视为正例(positive bag),正常视频视为负例(negative bag)。
2. 中间绿色部分 (Completeness of Pseudo Labels)
这部分说明在文章的3.2节。
这里还是以一个视频举例。经过特征提取后,这个视频将被切成 S 份,每份都有一个对应的特征向量,组成一个该视频对应的特征向量集。为方便叙述,和作者在第 4 章里实际操作的一样, S 取 32。
这个视频的32个特征向量将分别输入到多头分类器的每个头里,这里我们假设它有两个头(因为作者实际上在论文里只用了两个头),这两个头部分类器都是由3个全连接层组成的神经网络,参数也不一样。头部分类器表示为如下式子:
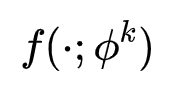
每个头都旨在输出哪些特征对应的视频片段是有异常事件的。但在这之前,还有一些事要做。
这里首先我们要先得到异常分数,再对所有头输出的异常分数取均值,最后通过 Sigmoid 激活函数得到片段级的异常标签(在0到1上分布)。异常分数越高,说明这个特征向量代表的这个片段更有可能是含有异常事件的。异常分数用特征向量过一遍分类器即可得到,如下式表示:
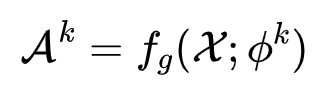
再进行取平均:(这里假设是两个头)
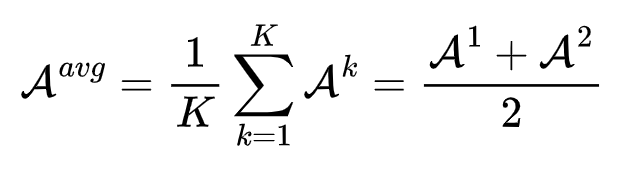
最后通过激活函数获得片段级的异常标签集:
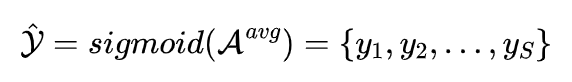
通常到这里就已经提取到一定精度的伪标签了,但是为提升模型性能,作者又通过多个损失函数对模型做了进一步约束,分别是多样性损失(diversity loss)、分数求L2范数后的正则化(regularization term on the norm)、基于 hinge 的排名损失(hinge-based ranking loss)
a) 多样性损失
在多头分类器处理视频特征集时,为使分类器检测到尽可能多的异常事件,需要鼓励这 2 个头的异常分数概率分布彼此不同。
异常分数的分布用到了 softmax 函数,如下式所示:
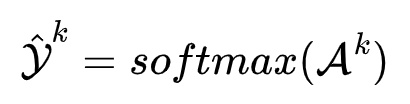
接着使用多样性损失函数,使训练时这两个头的分布差异尽量大。多样性损失的公式如下式表示:
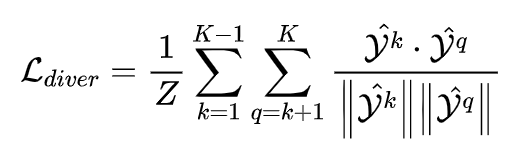
其中 Z 的计算方法如下式表示:
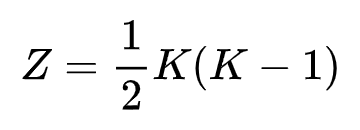
由于我们只用了两个头,多样性损失可以简化为下式:
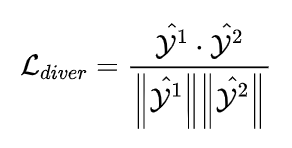
b) 分数求L2范数后的正则化
为了防止模型过于依赖某个头分类器的预测,因此需要平衡各个头分类器的输出,这里就将每个分类器输出的异常分数求L2范数(也就是欧式距离)后再进行正则化运算,得到又一个损失函数如下式表示:
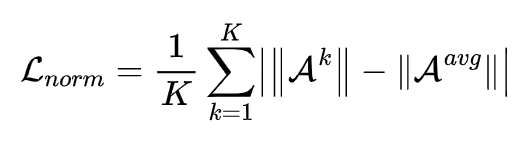
c) 基于hinge的排名损失
在这里需要约束正例(异常片段)的最高分数大于负例(异常片段)的最高分数,也需要最大化正负实例之间的分离度,使正常片段和异常片段尽量区分开,使用基于hinge的排名损失如下式所示:
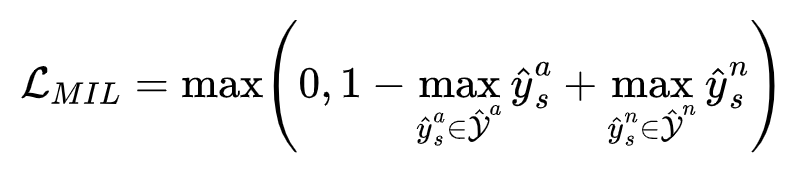
综上,将三种损失函数进行统合,就得到了多头分类器最终的损失函数:
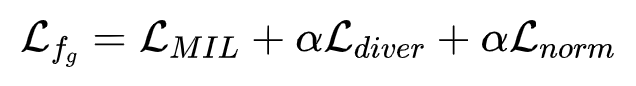
用该损失函数来训练多头分类器,提升输出的伪标签集质量。在 UCF-Crime 数据集上,作者将 α 取为 10,在TAD 和 XD-Violence 数据集上 α 取为 0.1。
3. 右边蓝色部分 (Uncertainty of Pseudo Labels)
这部分说明在文章的 3.3 节,文章中展示的算法伪代码如下:


第 7 行至第 18 行即这一部分的工作。
迭代需要的模型即上一节训练好的多头分类器,但是训练还需要一定的数据。作者不直接使用上一节生成的伪标签集,而是将伪标签进行不确定性估计、并选择不确定性最小的一部分数据进行训练,迭代得到的新模型继续重复此操作直到模型收敛。
第一次迭代 我们需要先准备好伪标签集,这里用加入了蒙特卡洛-Dropout法的多头分类器输入训练集里的视频,进行 m 次随机前向传播训练,得到视频异常分数,并通过Sigmoid激活函数得到片段级异常标签集。如下式表示:
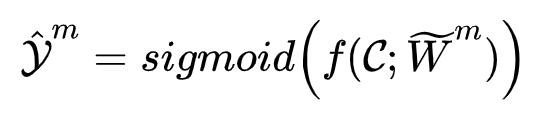
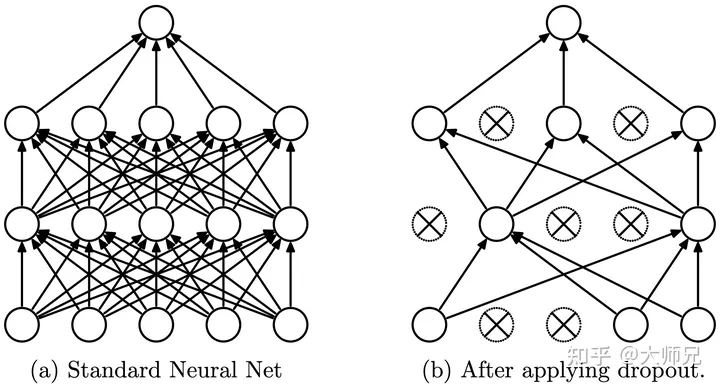
(在这里我查阅了有关dropout层和 MC-Dropout 层的相关知识点。)
将这m次前向传播得到的标签进行平均处理,得到最终的片段级伪标签集,如下式所示:
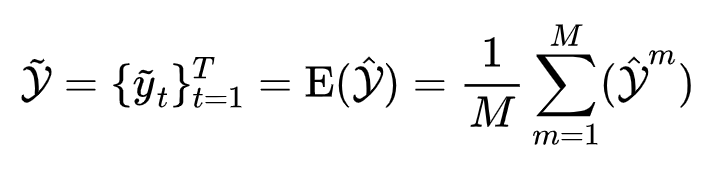
这还不是迭代的时候用的标签集,还要再计算一下这些标签的不确定性,选出不确定性最低的标签出来。
这里用到的是异常分数分布的方差,编程时可以通过求协方差矩阵的对角线元素获得,计算公式如下:
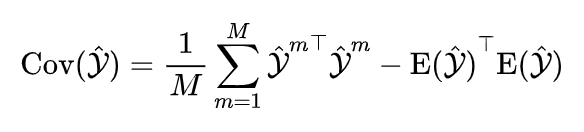
将伪标签的不确定性按从小到大排序,保留不确定性分数最低的前 R% 的片段,以及他们对应的特征向量和伪标签。这些片段及对应的伪标签就是“可靠的”,文章把获得这些片段及特征向量的过程称为“挖掘”。
但是还没有结束。
为了将片段上下文关系纳入考量,使可靠片段拥有上下文关系,所有片段的特征会放进一个记忆池中,当挖掘到一个可靠片段,其特征为 c 后,从记忆池选出相邻前 w 个片段,并组成特征集 H,将 H 执行平均池化得到 H‘,然后将 c 与 H’ 连接,得到新的该片段的特征 c‘。这个特征才是最后训练要用到的特征。作者将这个过程称为长期特征记忆(long-term feature memory)模型。
将所有挖掘出来的可靠片段对应的特征向量都过一遍长期特征记忆模型后,得到的特征集就是”可靠的”特征集了。
最后将这些可靠的时序特征集和可靠的片段级伪标签集用来训练多头分类器,使用二元交叉熵损失函数,就能得到初次迭代后的模型。
后续迭代 将上一次迭代得到的模型再次拿来训练,重复上述工作。
这样用经过层层严选提炼出来的数据进行训练,模型效果就会好很多。
不过这个模型可能没有考虑到泛用性,对于训练过程中未出现的场景,并不清楚其表现出的效果如何。
总结
本文是在伪标签上下功夫,力求异常视频伪标签的完整与准确,并在提升这两个指标上做出了自己的改进。框架本身并不算很复杂,有一些前置知识都是深度学习里的,或多或少都有一些了解,但是为了搞懂这些损失函数确实花了不少精力。搞懂下来之后好像收获也不是特别多,而且还费了不少时间,以后应该避免拘泥于不必要的细节。