名称:实时弱监督视频异常检测
链接:openaccess.thecvf.com/content/WACV2024/papers/Karim_Real-Time_Weakly_Supervised_Video_Anomaly_Detection_WACV_2024_paper.pdf
一篇关于视频异常检测的论文,简要整理了一下。文章提出了第一个实时且端到端训练的弱监督视频异常检测(wVAD)算法,称为 REWARD (Real-Time End-to-End Weakly Supervised Video Anomaly Relevance Detector)。
所谓的实时,即相比起需要把一整个视频送进模型里才能检测出异常的方法来说,作者提出的模型具有很短的决策周期(6.4秒),能在短时间内输出当前是否存在异常片段,以达到实时检测的效果。
所谓端到端,输入直接就是原始数据,输出直接就是最终结果,当下流行的wVAD流程,需要先提取特征,这个特征集才是模型的输入,再进行特征编码,然后再以二分类问题的解法得到异常视频片段预测定位,而作者所提出的方法简化了流行的wVAD方法,直接输入带有异常片段的视频,并且性能更优,如下图所示。
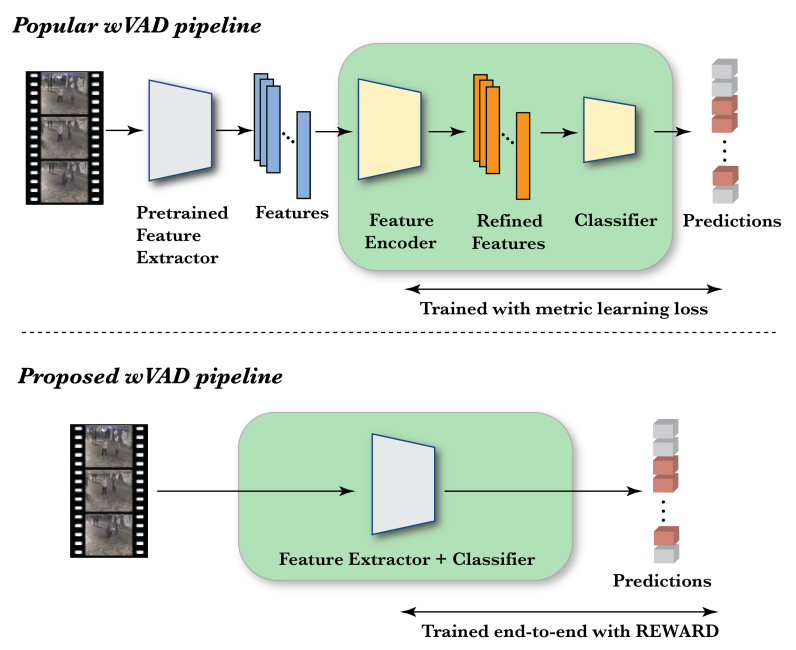
作者的方法在 wVAD 数据集(如 UCF-Crime 和 XD-Violence )上的性能优于决策周期为273秒的最先进方法。
方法论
作者的总体训练框架如下图所示。
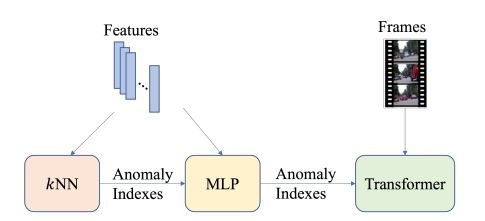
简单概述有三步:
1. 用 提取的视频特征,训练 k近邻 网络,得到 异常片段索引;
2. 用 异常片段索引与视频特征,训练 多层感知机,得到 高质量异常片段索引;
3. 用 带有高质量异常片段索引的异常视频,训练 大型视频模型,如Transformer。
作者指出,端到端训练可以通过消除特征细化(feature refinement)的需求来简化整个机器学习流程。此外,它可以带来更好的实时性能,模型可以直接从原始输入数据中学习任务特定的表示,而无需进行特征聚合(feature aggregation) 。
由于异常检测训练时,异常视频的标签通常都不支持有监督学习,所以度量学习损失是一个不错的损失函数。度量学习损失的目标是最小化同类样本之间的距离,并最大化不同类样本之间的距离,从而提高特征的质量。
在之前的论文解读中,是遇到过度量学习损失的,比如这篇提到的基于hinge的排名损失(点击跳转)。
但是度量学习损失不能用在作者提到的端到端训练模型中。以MIL排序损失为例,它需要同时训练相同数量的异常视频和正常视频,以最大化两组样本之间的分离度,这会导致两个问题:在单个GPU中同时处理大量视频片段需要大量的内存,而且特征提取器的参数数量比特征编码器多几个数量级,如下图所示。
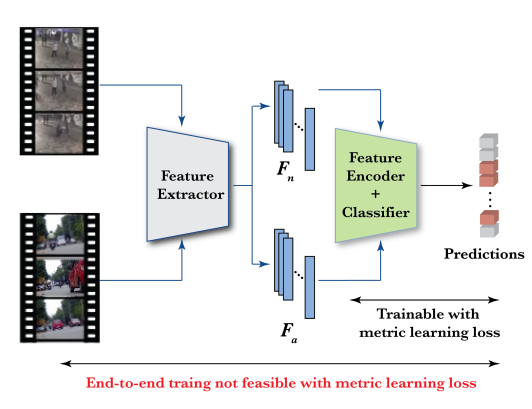
于是作者的替代方案是:为异常视频生成片段级的伪标签,并用更节省内存的损失函数(应用中使用了二元交叉熵损失,BCE)替换了度量学习损失函数。
为生成片段级伪标签,作者提出了REWARD网络,如下图所示。
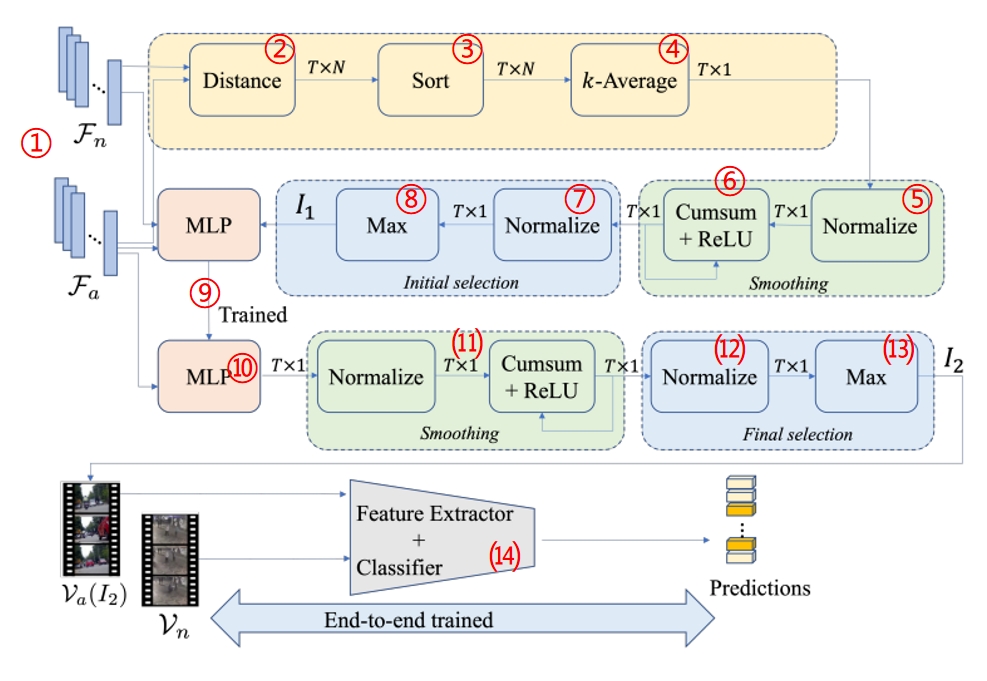
每一个环节的说明如下:
① 各正常视频和异常视频划分为 T 个片段,并使用 Uniformer-32 提取特征,以获得正常视频和异常视频的特征表示,分别为:(其中 P 是特征向量的维度)
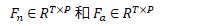
② 将异常视频特征集 Fa 中的每个片段的特征与正常视频特征集 Fn 中的所有特征向量进行比较,计算它们之间的欧几里得距离,生成一个 T×N 的距离矩阵。
③ 对每一行中的 N 个距离按升序进行排序。
④ 对每一行应用平均池化层,只取前k个元素的平均值(即 k近邻,kNN,应用时取了 k = 20)。
每个 kNN 距离提供了异常视频中每个片段与正常片段的相似度估计。距离值越小,表示与正常特征的相似度越高,反之亦然。
⑤ 减去平均值,将 kNN 距离变为零均值:
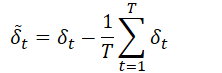
⑥ 循环应用累积和,并使用ReLU激活函数计算每个片段的异常分数:
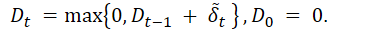
异常视频中片段的异常分数 Dt ,如果与正常片段相似的会接近 0,而与正常片段不太相似的会取正值,因此具有较大 Dt 值的片段将作为较优候选。
⑦ 将视频中每个片段的异常分数 Dt 除以视频中的最大值进行归一化:
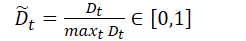
⑧ 对第 j 个视频有:选择归一化的值大于阈值 λ ∈ (0.5, 1) 的片段收集起来,作为初始异常片段索引集合:(应用时取的 λ = 0.8)
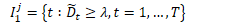
将所有异常视频中的初始集合组合起来,形成集合 I1,集合里面的片段异常分数都很高,用于多层感知机的训练。
⑨ 多层感知机的训练: I1 中异常片段标记为 1,正常片段标记为 0,损失函数为BCE。
⑩ 所有异常视频中的片段都会通过训练好的MLP来估计它们异常的概率 pt。
⑾ 同⑤和⑥,重复平滑操作,将 pt 减去均值,使其变成零均值,循环累积和之后得到每个片段的异常概率 Rt。
⑿ 同⑦, Rt 除以最大值,归一化,使其在 0 到 1 上分布 (符号为 Rt,R上面一个大波浪)。
⒀ 方法同⑧,不同之处在于其阈值要低一些,这里取的视频中片段异常概率 Rt 归一化后的平均值:
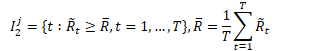
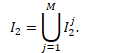
所有视频中片段的归一化异常概率高于均值的都收集起来,最终得到经过严选的异常片段索引 I2,至此可将 wVAD 任务转化为二分类问题。
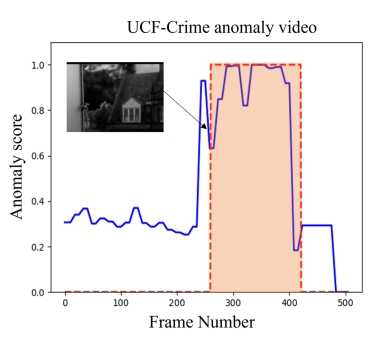
⒁ 有了卓越的训练样本,用BCE损失以端到端的方式训练特征提取器,分类层使用带 Sigmoid 激活函数的单个神经元分类器计算异常相关性概率。实战时和实际标记高度吻合,如下图所示。
应用
作者使用的数据集:UCF-Crime 和 XD-Violence,这两个数据集的介绍就不在此赘述,贴个链接吧:异常检测数据集收集与介绍分析_Johngo学长 (johngo689.com)
能客观评估模型表现,作者只使用了视频信息,而丢掉了其中的音频信息。
评价指标:模型在 UCF-Crime 数据集上的性能使用ROC曲线下的面积(AUC)指标来评估,以及在 XD-Violence 数据集上使用平均精度(AP),即P-R曲线下的面积来评估。
文中还以每秒帧数(fps)的形式展示了算法的计算效率结果,以评估其实时推理能力。
结果:
在 6.4s 附近的决策周期内没有能打的,实时推理能力很强。(但还是没上90%)
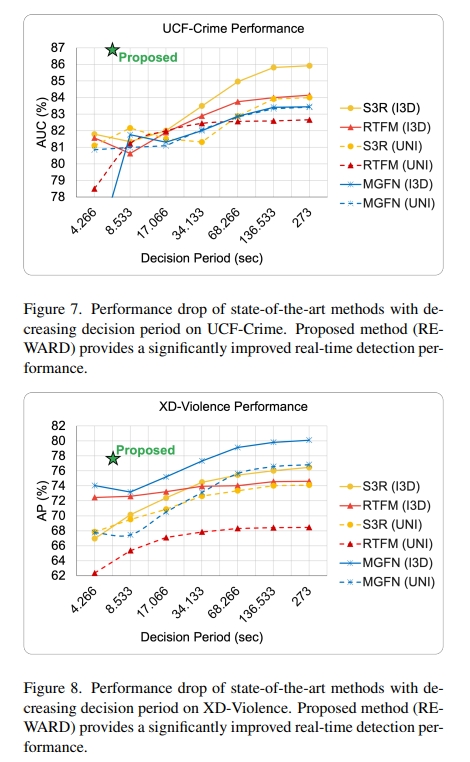
作者的方法基于 Uniformer-32 在 Nvidia RTX-2070 GPU 上的推理计算速率为63.3 fps。以63.3 fps的速度能够在0.5秒内处理32帧,从而导致总共6.9秒的决策延迟。在 Intel Core i7 8700K CPU 上,对于 UCF-Crime 数据集,使用 Uniformer-32 进行训练期间的 kNN 计算大约需要 5 小时。